snort가 패턴매칭이라면 엘라스틱서치(ELK)는 이상징후 분석을 활용하기 위한 프로그램이다!
또한 elk의 가장 큰 목적은 Dashboard를 만들 수 있다는 것이다.
데이터 정확도가 보장이 안되기 때문에 패턴매칭으로는 불가능하다.
[4강] ElasticSearch를 이용한 이상징후감지
| ELK의 개념 |  ELK에 대한 내용은 아래 링크에서 정리해 놓은 내용을 통해 더 자세하게 확인할 수 있다.  이러한 구조를 ELK에서는 mapping이라는 이름으로 정의해 놓는데, 여기서 field를 정의하는 것이 주목적이다. |
1. ELK 설치하기
T-Academy에서 제공하는 사전에 미리 제작된 repo파일로 실행시키기

elk도 java를 기반으로 동작되기 때문에 java설치 후 elk를 설치해야한다.
yum instll javayum install elasticsearch -yWINDOW용
다운로드 받아서 압축 풀고 실행하면 끝이다.
아래 링크 참고
http://sanghoon9939.tistory.com/52
01) Window에서의 Elastic설치
[윈도우에서 elasticsearch] "사정상 window에서 elasticsearch를 사용해야할 상황이 있어 설치를 하게 되었다. 설치를 하는 과정에서 생긴 문제점과 시행착오를 적어보고자한다." - elasticsearch란? - 먼저, el
sanghoon9939.tistory.com
2. 다운 받은 폴더 확인하기
엘라스틱 서치는 기본적으로 CONFIG에서 수정할 필요가 거의 없이 실행 가능하다.
* 별도로 다른 네트워크에서 접속해야하는 경우에는 아래와 같이 주석을 풀어주면 된다.

3. elasticsearch 실행시키기
bin 경로의 elasticsearch.bat 파일 클릭 후 elasticsearch or elasticsearch.bin 명령어 입력

started 명령어가 뜨면 실행이 된 것이다.
4. localhost로 접속하기
elasticsearch의 기본 port는 9200이다.
chrome창에 localhost:9200 입력하여 웹사이트에서 확인하기

5. kibana실행시키기
config 내에서 기본 포트는 5601이다.

우리는 localhost에서 확인하기 위해서 0.0.0.0을 주석처리하고 위의 localhost의 주석을 해제한다.
또한 Kibana의 경우에는 Elasticsearch내에 저장된 데이터를 가져와서 데이터로 시각화해주는 툴이다.
따라서 Elasticsearch와 통신해야하기 때문에 주소를 알고 있어야 한다.

우리는 지금 여기서 default로 9200을 설정해 두었는데 실제로 할 때는 다른 ip로 설정을 바꿔줘야 한다.
bin폴더 내 kibana.bat파일 실행후 kibana.bat 입력하여 실행시키기

그럼 localhost 5601port로 이동하면 다음과 같이 확인할 수 있다

6. logstash에서 연동하기
logstash폴더 역시 bin폴더로 이동한 후 logstash 실행하기
이때 명령어는 앞선 명령어들과 달리 옵션을 추가해 주어야 한다.
logstash -f d:\sample.conflogstash에 대한 내용은 공식 홈페이지의 input, filter등이 자세하게 설명되어 있다. 참고!
https://www.elastic.co/kr/logstash
Logstash: 로그 수집, 구문 분석, 변환 | Elastic
Logstash를 처음 사용하시나요? 바로 실행하실 수 있습니다. 동영상 보기 Logstash를 이용하여 CSV 파일을 구문 분석하고 Elasticsearch로 수집하는 방법을 알아보세요. 동영상 보기 Elastic 공인 엔지니어
www.elastic.co
여기서 sample.conf 내용은 임의로 작성한 것이고 아래와 같이 작성하면 된다.
input {
file {
path => "d:/sample.log"
start_position => "beginning"
sincedb_path = "nul"
}
}
filter {}
output {
elasticsearch => { hosts => "localhost:9200" }
stdout { codec => "rubydebug"}
}* 참고로 우리는 sample.log파일을 이용한다. 이는 sample.log를 강사님이 미리 준비하셨다.
* sincedb_path를 null로 설정하면 반복적으로 테스트해도 같은 데이터를 읽어올 수 있다.
file옵션 사용하는 이유는 log파일 sample을 분석할 것이기 때문이다.

실제로 연동을 끝마치면 위와 같이 출력된다.
ERROR가 뜨고 있는데 이는 Elasticsearch와 통신이 잘 안되고 있어서이다. 위에 elasticsearch 명령어가 빠져서 에러가 난 것이다.
7. INDEX에서 데이터 확인하기


위와 같이 INDEX를 등록하면 DISCOVER탭에서 데이터를 확인할 수 있다.
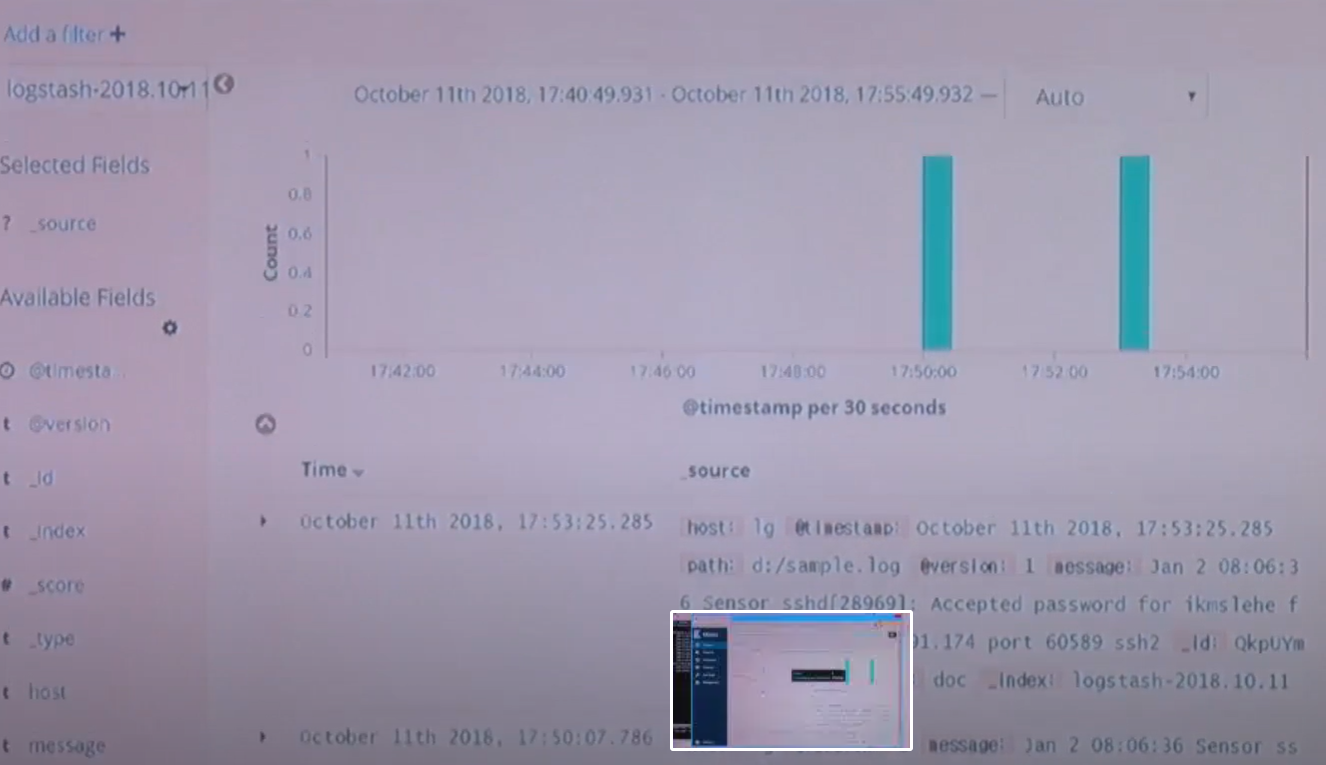
좀 더 다양한 분석을 하려면 아래 필드를 분리해주는 것이 필요한데 이는 filter 적용을 통해 가능하다
input {
file {
path => "d:/sample.log"
start_position => "beginning"
sincedb_path = "nul"
}
}
filter {
grok {
match => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"
}
date {
match => ["timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss"]
}
}
output {
elasticsearch => { hosts => "localhost:9200" }
stdout { codec => "rubydebug"}
}* grok필터는 정규표현식으로 데이터를 쪼개주는 필터이다.
강의에서는 grok필터에 따로 정규표현식 한 내용을 나누어 준 것 같은데 나는 너무 긴데 치기 힘들어서 걍 공식 홈페이지의 예시를 가지고 왔다. 따로 칠 사람은 아래와 같이 치면 된다.

timestamp를 적용하면 아래와 같이 쪼개서 확인할 수 있다.

추가로 visualize category에서 원하는 그래프를 또 그릴수 있다.
약간 방식은 google studio 또는 GA같은 느낌이고, Metrics, Buckets등을 통해 그래프를 그릴 수 있다.

POINT는 필드 분류에 대한 내용인데 이 부분은 그만큼 로그를 다양한 관점에서 고민해야 나올 수 있는 해답이다
'개발 > 보안' 카테고리의 다른 글
| [개인정보보호 포털] (신)개인정보보호법 이해하기 (2강) (1) | 2020.12.29 |
|---|---|
| [개인정보보호 포털] (신)개인정보보호법 이해하기 (1강) (9) | 2020.12.29 |
| [T academy]데이터 분석 관점에서의 네트워크 보안 (Snort) (0) | 2020.12.29 |
| [T academy]데이터 분석 관점에서의 네트워크 보안 (네트워크 보안 개념) (0) | 2020.12.28 |
| [개인정보보호 포털] 일반인 개인정보보호 온라인 교육 (1) | 2020.12.28 |